![]()
![]()
Licenciatura en Estudios Internacionales
Taller de Estadística: Introducción a R
Prof. René Canales
Asistente de Investigación FONDECYT 1250518
Bremen International Graduate School of Social Sciences (BIGSSS)
Universität Bremen
Asistente de Investigación FONDECYT 1250518
Universidad de Santiago de Chile, Abril 2026
¿Qué es R?
R es un lenguaje de programación estadística de código abierto, diseñado para:
- Análisis estadístico y modelamiento
- Visualización de datos
- Investigación reproducible
- Ciencia de datos
Nota
R es gratuito, multiplataforma y tiene una comunidad académica muy activa.
![]()
Creado por: Ross Ihaka y Robert Gentleman (1993)
Versión actual: R 4.x
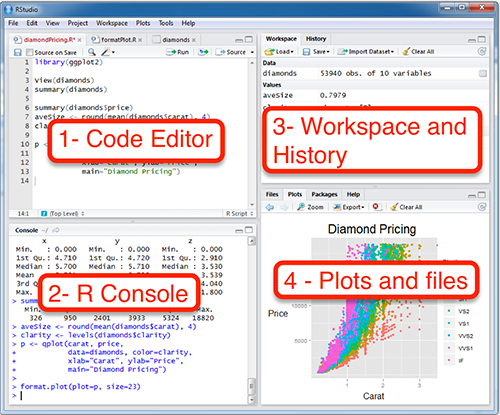
Componentes de RStudio
La interfaz de RStudio tiene 4 paneles principales:
① Script / Editor
Donde escribes y guardas tu código R.
② Consola (Console)
Donde se ejecuta el código y ves los resultados.
③ Entorno (Environment)
Muestra los objetos y variables activos.
④ Panel Inferior Derecho
Archivos, Gráficos, Paquetes y Ayuda.